
Detección de objetos en imágenes: YOLO algorithm
YOLO es un algoritmo de detección de objetos en imágenes (You Only Look Once), que es el resultado de un modelo de redes neuronales convolucionales (CNN). Se explicará el paso a paso y los requerimientos para su desarrollo la versión v3 del modelo.
En el área de detección de imágenes la práctica antes de YOLO es usar varios trozos de la imágen, buscando el objeto en estas sub-imágenes. YOLO usa un método distinto a sus predecesores; observa la imágen completa solo una vez a través de una red neuronal para detectar objetos por una única vez, por eso su nombre. La popularidad se debe a su rapidez en el procesamiento.
El desarrollo oficial de YOLO está disponible en darknet. Además, está disponible un github para su uso darknet_repo.
-
Librería
opencv-python(renombrada comocv2)La librería cv2 se relaciona a computer visión, y es el tratamiento de imágenes y videos. El modelo YOLO se encuentra pre-entranado en la librería
cv2mediante el módulodnn(deep neural network), dando a los usuarios la habilidad de ejecutar modelos de deep learning pre-entrenados dentro de la librería opencv. El módulo dnn no está diseñada para entrenar un modelo de redes neuronales, y es usada en la predicción de detección objetos en imágenes/videos en modelos ya calibrados. Estos modelos son compatibles con librerías/frameworks como Torch y TensorFlow. -
Como usar el modelo YOLO en Python usando OpenCV
-
Instalar las librerias numpy y opencv-python (renombrada por
cv2). Para la visualización de las imágenes es necesario instalar matplotlib.
-
Archivos requeridos
- Imágen de entrada
- Configuración del modelo YOLO yolo3.cfg.
- Pesos del modelo YOLO de pre-entrenamiento yolo3.weights.
-
Archivo de texto que contiene las clases de nombres de 80 objetos a identificar en coco (common objets in context). Leer las clases de objetos en una lista, denominada class_list coco.names.
classes = open('coco.names').read().strip().split('\n')
-
Preparar el input de datos y el modelo a utilizar
Leer la imágen a utilizar.
img = cv2.imread('imagen.jpg')Cargar el modelo ya entrenado usando el módulo
dnndecv2.net = cv.dnn.readNetFromDarknet(yolo3.cfg, yolo3.weights) #CNN in openCV net.setPreferableBackend(cv.dnn.DNN_BACKEND_OPENCV) #options backend net.setPreferableTarget(cv.dnn.DNN_TARGET_CPU) #options modelEl input del modelo es un objeto de tipo blob. Usar la configuración
blob = cv2.dnn.blobFromImage(img, 1/255.0, (416, 416), swapRB=True, crop=False) #encode image to process in model net.setInput(blob)net.setInputprepara la imagen de entrada a través de la red neuronal para obtener los outputs. -
Estructura del modelo
El modelo tiene la siguiente arquitectura
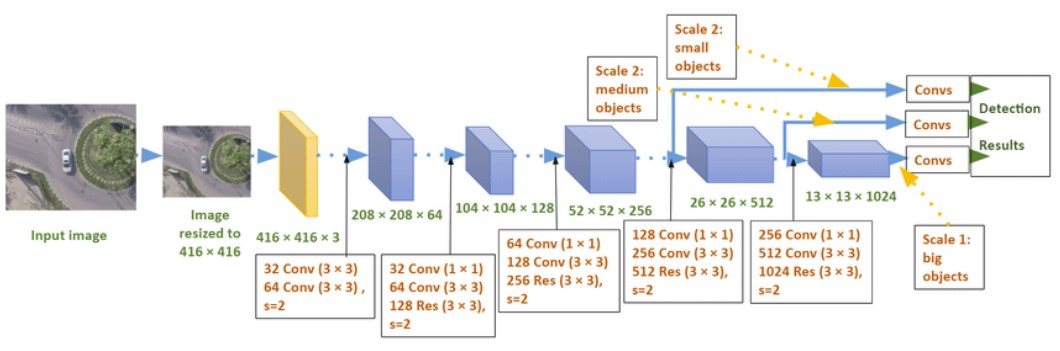
En este caso hay 3 outputs según el tamaño del objeto (representado por diferentes tamaños de las convoluciones), y es para la detección de objetos en distintas grillas en relación a la imágen.
Estos outputs no están conectados a un siguiente nivel en el modelo.
#Select output layers ln = net.getLayerNames() ln_out = [ln[i - 1] for i in net.getUnconnectedOutLayers()]Se extraen y apilan los outputs del modelo en un solo vector.
outputs = net.forward(ln_out) #Get the outputs of the model outputs = np.vstack(outputs) #Stack in one column the outputs of the model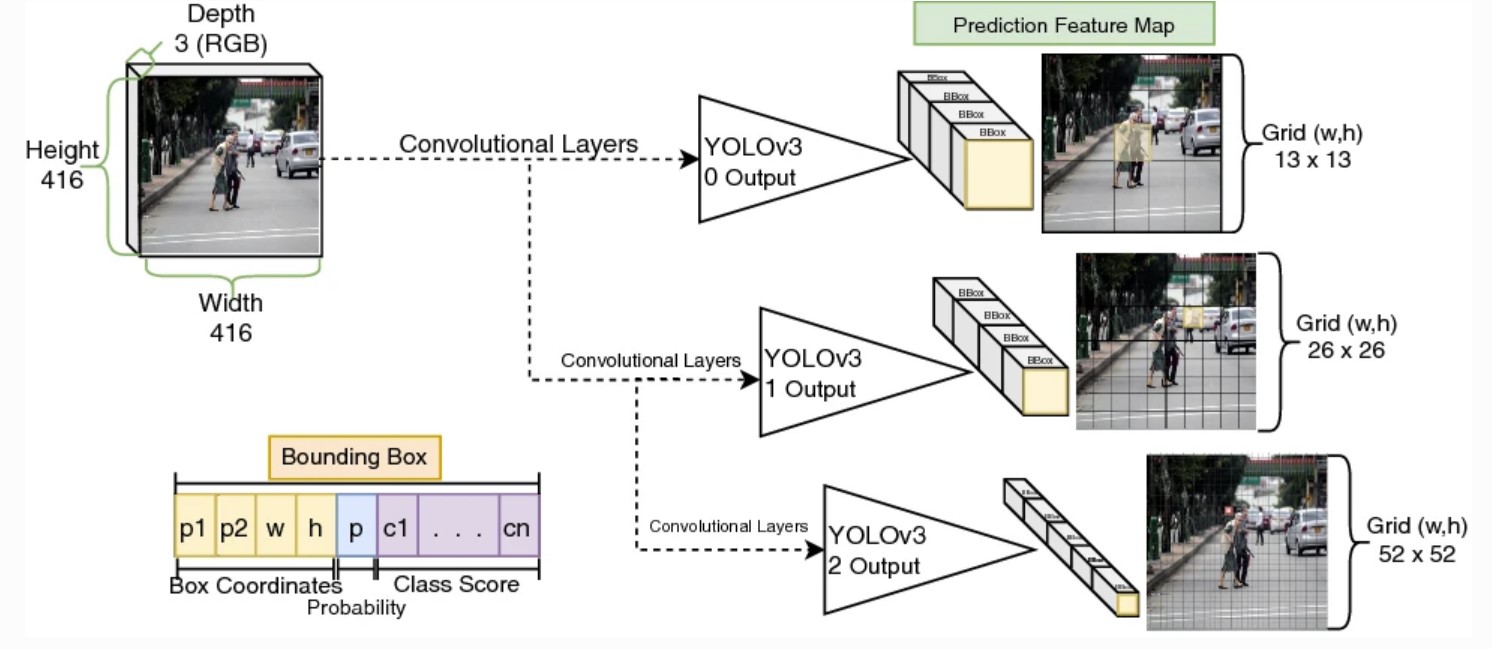
El modelo tiene 85 parámetros de salida, siendo los primeros dos la posición central del objeto (p1,p2), los siguientes dos parámetros son la distancia horizontal y vertical entre el objeto y su posición central (w,h); el siguiente parámetro se relaciona con la probabilidad de detección de al menos uno entre los 80 objetos; y los últimos 80 parámetros se relacionan a la probabilidad de detección de cada objeto en coco.names.
-
Predicción y non-max suppression
La última etapa es ignorar las detecciones poco probables (determinar un threshold ~ 0.6) y descartar las detecciones sobrepuestas del mismo objeto. Non-max suppression remueve las detecciones con mayor tasa de sobreposición.
cv.dnn.NMSBoxes(bboxes, confidences, score_threshold, nms_threshold)
El último paso es dibujar los recuadros de los objetos detectados en la imágen. -
Resumen
En este post se describió como user el módulo dnn de OpenCV con un modelo de detección de objetos YOLO pre entrenado. Puedes usar el ejemplo en el repositorio yolo-v3.
El resultado de una fotografía icónica: Una visita a la plaza de Tiananmen, Pekín, China.

Gracias por llegar hasta aquí, espero que haya sido de ayuda.
-
-
Referencias
